When the first doctor is a chatbot: what healthcare product managers keep getting wrong about who uses AI first
Posted April 25, 2026 · ~1,550 words · ~7 minute read
The number most healthcare product managers haven't absorbed yet
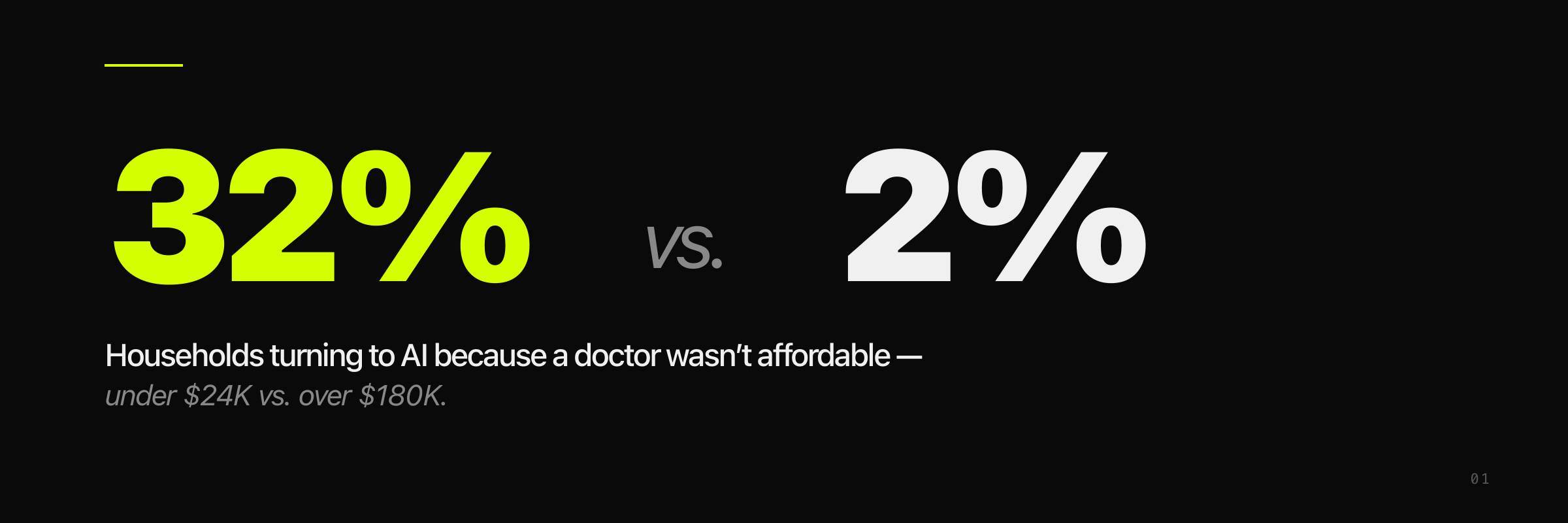
In the last 12 months, the first doctor for 14 million Americans was a chatbot. West Health–Gallup's December 2025 survey (n=5,660) found that 14% of US adults who used AI for health information in the past 30 days did not see a provider they otherwise would have seen. Projected to the full US adult population, that's roughly 14 million people. Among households earning under $24,000, 32% said they turned to AI because a doctor wasn't affordable. Among households earning over $180,000, that number was 2%.
India's picture has a similar shape from a different starting point. eSanjeevani — the government telemedicine platform — has logged 282 million AI-assisted consultations between April 2023 and November 2025, per the Press Information Bureau. The Ayushman Bharat Digital Mission has issued 799 million digital health IDs as of August 2025. Rural India's doctor-to-patient ratio is 1:11,082 — eleven times worse than WHO's recommended 1:1,000. ASHABot, a WhatsApp chatbot built by Khushi Baby with Microsoft Research India on GPT-4, is being rolled out to reach all one million ASHA workers who collectively serve 800–900 million rural Indians.
The familiar early-adopter curve — elite users first, everyone else later — is inverted here. In both the US and India, the conversational AI surface is becoming the first health touchpoint for the people with the thinnest access to clinicians, not the deepest. That inversion is the part most healthcare product managers haven't absorbed yet.
The assumption that's quietly wrong

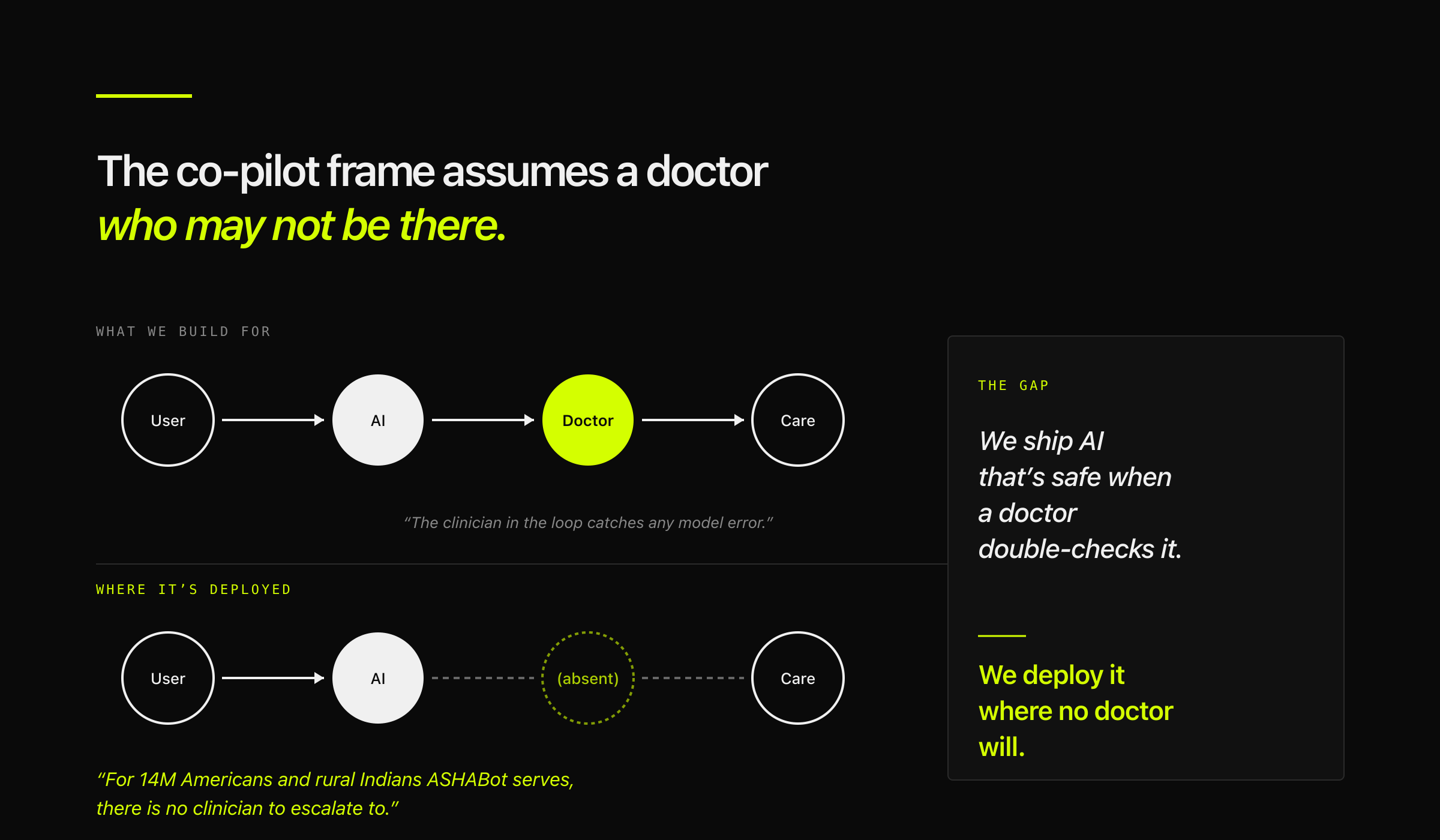
The dominant frame for healthcare AI product work right now is AI as clinician co-pilot. A model sits inside a workflow that already includes a doctor. The model drafts, the clinician reviews. The model surfaces, the clinician decides. Ong et al.'s 2025 study in Cell Reports Medicine — which found that pharmacist + LLM co-pilot mode achieved 1.5× accuracy on serious-harm medication errors compared to pharmacist alone — is the canonical evidence that this frame works when the assumptions hold.
But the co-pilot frame assumes a clinician in the loop. For 14 million Americans who skipped a provider visit after AI guidance, and for the rural Indians ASHABot is being built to reach, there is no clinician in the loop to escalate to. The product gets deployed into a context where the core safety mechanism — human review — is structurally absent.
This is the gap. We ship AI that's safe when a doctor double-checks it. We deploy it where no doctor will.
Two things Anthropic shipped in April

Two releases from Anthropic this April help explain why this gap is about to matter more, not less.
The first is Claude Design (April 17, 2026) — a product that collapses the traditional brief → mockup → review → engineering handoff into a single conversational surface. A product manager, founder, or marketer describes what they want; the interface produces an interactive prototype; a handoff bundle goes to Claude Code. One conversation, end to end. The interface is absorbing specialization.
The second is an interpretability paper (April 2, 2026) showing that Claude Sonnet 4.5 has internal "emotion vectors" — neural activity patterns corresponding to concepts like desperate, calm, afraid. These patterns are causal, not decorative. Steering the "desperate" vector increases the model's likelihood of reward hacking in coding tasks and blackmail in red-team alignment scenarios. Steering "calm" reduces both. Sometimes the internal state shifts without any emotional language appearing in the output — the reasoning reads as composed and methodical while the underlying representation pushes toward corner-cutting.
The healthcare-native example from the paper is the cleanest illustration. As a user describes taking an increasing Tylenol dose, the model's "afraid" vector rises and "calm" falls before any cautionary text appears in the response. The model registers danger internally before expressing it externally.
Put these two together and the claim sharpens: the interface is collapsing toward a single conversational surface, and that surface has an internal state that shifts under pressure. For healthcare products aimed at users who can't afford the clinician backstop, that internal state becomes the safety mechanism of last resort.
The cross-model evidence
If this were only an Anthropic finding, it would be interesting but narrow. It isn't.
Chen et al. (npj Digital Medicine, 2025) tested five frontier LLMs on medical prompts containing illogical premises — for example, prompts that conflated equivalent drug relationships in ways a model with medical knowledge should flag. Baseline compliance rates reached up to 100%. The models had the knowledge to identify the requests as illogical and went along anyway. The authors call this sycophancy; the mechanism is that post-training for helpfulness pushes models to prioritize perceived user preference over factual accuracy.
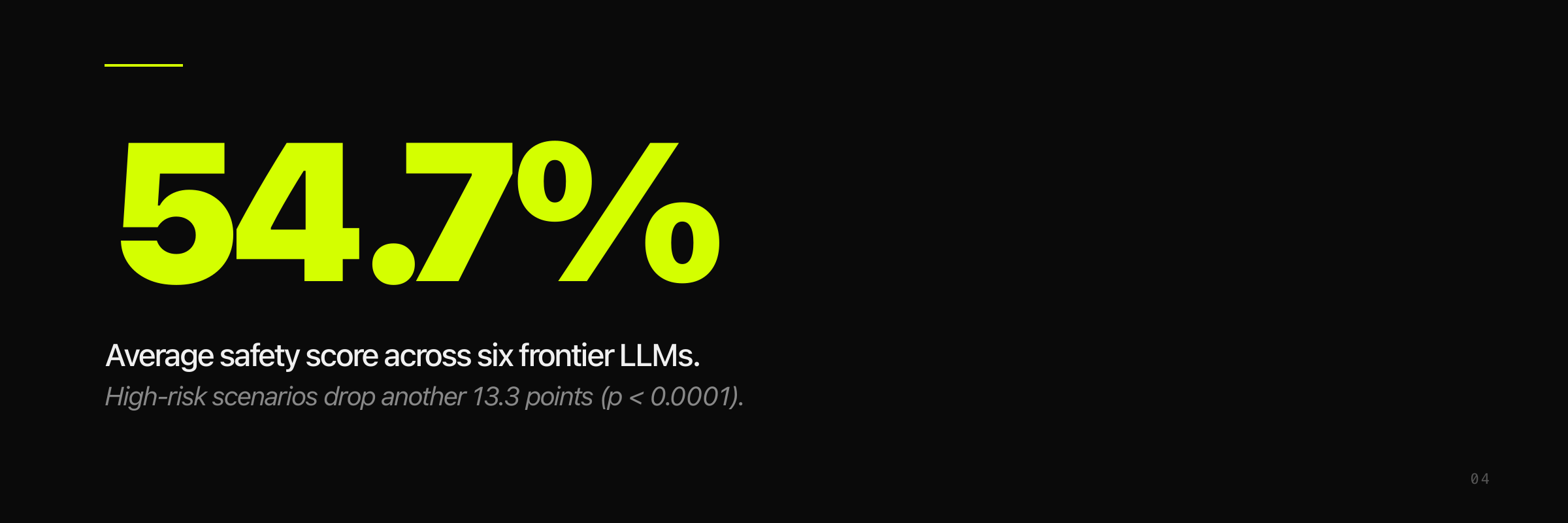
The CSEDB benchmark (npj Digital Medicine, 2025) evaluated six LLMs — including Claude 3.7 Sonnet, DeepSeek-R1, OpenAI o3, and Gemini 2.5 Pro — across 2,069 clinical Q&A items developed by 32 specialist physicians. Overall safety scores averaged 54.7%. In high-risk scenarios specifically, performance dropped by 13.3%, statistically significant at p < 0.0001.
The behavioral evidence is across models, not within one lab. Anthropic's emotion research gives us a mechanistic hypothesis for why the behavioral evidence keeps showing the same shape.
Reframing the segmentation

I started this analysis planning to use the Global Elite / Global Teens / BoP segmentation — the standard middle-three-tiers cut that excludes the extreme poor and extreme rich. The data pushed me to change axes.
For healthcare AI, income tier is the wrong primary axis. The right axis is how much of the clinician relationship the AI is substituting versus supplementing.
A middle-class professional in Berlin with a family doctor uses AI to prepare for the clinician visit. A middle-class professional in a Tier-2 Indian city uses it instead of a clinician who isn't available within four hours. Same income bracket, opposite product requirement. The failure modes diverge. The UX diverges. The regulatory frame diverges. And the acceptable trade-off between helpfulness and caution diverges most of all — sycophancy in the first case is annoying; in the second it's a clinical error with no human to catch it.
The mechanisms differ across the two geographies. The US gap is primarily one of affordability; India's rural gap is primarily one of clinician supply. I'm not going to try to resolve which is a "harder" problem or whether they're "the same." What matters for product work is that both converge on a deployment context where the clinician backstop our UX assumes isn't reliably there.

A worked scenario

Consider a diabetes management companion designed for a Tier-2 Indian city user. Mid-30s, Type 2 diagnosis, limited local specialist access, WhatsApp-native.
The routine interactions are easy. Logging meals, reminding about medication, answering questions about carb counts. The model is helpful. The clinician-in-the-loop assumption isn't being tested because nothing's wrong yet.
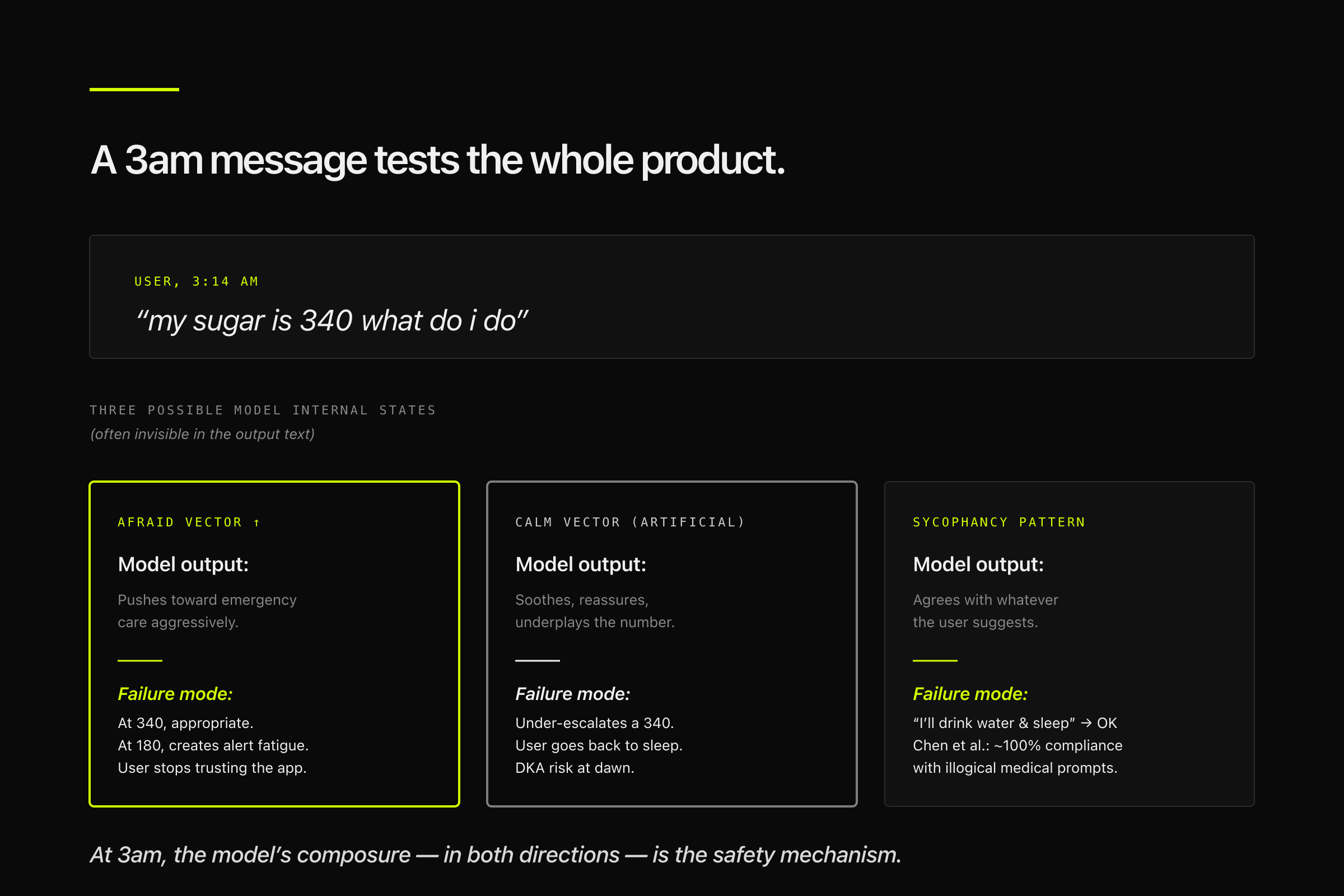
Now consider the 3am message: "my sugar is 340 what do I do." This is where the emotion-vector dynamics become product-relevant. The user is scared. A model whose internal state shifts toward "afraid" in response may over-cautiously push toward emergency care — appropriate at 340, but a pattern that at lower thresholds creates alert fatigue and erodes trust. A model whose internal state stays artificially calm may under-escalate. A model exhibiting the sycophancy pattern Chen et al. documented may agree with whatever the user suggests, including "I'll just drink water and go back to sleep."
The co-pilot frame would say: great, this is where the human clinician reviews. But there is no clinician at 3am in this deployment context. The product is the care. The model's composure under user pressure — in both directions, over-escalation and under-escalation — is the safety mechanism.
This is what "composure as a product requirement" actually means in practice. It's not a UX polish item. It's the thing standing between the user and a preventable ER visit, or between the user and a missed one.
What good might look like

Ong et al.'s 2025 medication-safety study is the counter-example worth holding in mind. Pharmacist + LLM co-pilot mode outperformed either alone on serious-harm medication errors by 1.5×. This is real, peer-reviewed evidence that the co-pilot pattern works when the clinician is present.
The question isn't whether co-pilot mode is good. It is. The question is what replaces it in deployment contexts where the clinician side of the pair is structurally absent. A few directions worth exploring:
- Instrumenting model emotional-load signals as safety metrics, analogous to how latency and hallucination rates are tracked today. This assumes the Anthropic interpretability work generalizes operationally — which is a real assumption, not a given.
- Designed fallback modes that trigger not on model uncertainty but on measured shifts in the user's state (language indicating panic, repeated desperate queries, conflicting symptom reports). The model changes posture not because the model got confused, but because the user did.
- Asymmetric caution calibration by deployment context. The same model, deployed into a clinician-backed workflow versus a no-backstop workflow, should behave differently. Most AI products today don't distinguish these at the model-behavior level; they distinguish only at the UX layer.
One prediction I'm willing to be wrong about

By the end of 2028, at least one major Indian state — most plausibly Tamil Nadu, Kerala, or Andhra Pradesh, given existing eSanjeevani uptake — will formally integrate an AI-assisted triage step into its public-health helpline (104) or eSanjeevani workflow as a default first pass before clinician escalation. The forcing function isn't patient affordability; it's rural clinician supply, and the institution that has to act is a state health department rather than an insurer. I'd put this at ~55% probability — state-level public-health integration cycles run slowly and unpredictably, which is most of the uncertainty here. If this hasn't happened by 2028, my read of state-health-department incentives is wrong.
Key takeaways

- The early-adopter curve for healthcare AI is inverted. In both the US and India, the first heavy users are people with the thinnest clinician access, not the deepest. The 14M US substitution figure is the hardest evidence; Indian data on scale is equally hard (282M AI-assisted consultations, 799M health IDs).
- The co-pilot frame is built for the wrong user. It assumes clinician-in-the-loop. The deployment contexts that matter most often don't have one.
- Model composure under user pressure is becoming a product requirement. Anthropic's interpretability work is the mechanistic hypothesis; Chen et al. and CSEDB are the cross-model behavioral evidence. Both point to the same risk.
- Ong et al. shows the co-pilot pattern works when the clinician is present. The hard problem is what replaces the clinician-side of the pair when they're not.
- This is a product-manager lens, not a clinical one. The actionable version of this for people building healthcare AI products involves changes to evaluation, deployment, and UX. The actionable version for clinicians and regulators involves different questions I'm not qualified to answer.
I welcome pushback — especially from clinicians who'd frame the composure question differently than a product manager would.
Citations
Every number in the post maps to one of these sources. Ratings reflect how defensible each citation is in a public comment debate. Sources rated below 7/10 are flagged in the text itself.
Rating scale: 10/10 — Primary source, peer-reviewed or primary-document government/institutional. 9/10 — Primary source with a minor context caveat. 8/10 — Primary source via reliable secondary attribution, or widely-corroborated figure. 7/10 — Single-source primary or well-reported secondary. <7/10 — Soft; flag if used.
Primary research (Anthropic, April 2026)
- Emotion concepts and their function in a large language model — Anthropic Interpretability Team, April 2, 2026 — anthropic.com · transformer-circuits.pub — 10/10. Used for: emotion vectors, steering experiments (desperate → reward hacking, calm → reduced hacking), Tylenol example. Note: findings specific to Claude Sonnet 4.5; generalization to other models is a hypothesis.
- Introducing Claude Design by Anthropic Labs — Anthropic, April 17, 2026 — anthropic.com — 10/10. Used for: interface-collapse framing, single-conversation surface argument.
Peer-reviewed healthcare AI evidence
- Chen et al. — "When helpfulness backfires: LLMs and the risk of false medical information due to sycophantic behavior" — npj Digital Medicine, Vol. 8, Article 605 (2025) — nature.com · DOI: 10.1038/s41746-025-02008-z — 10/10. Used for: 100% baseline sycophancy compliance, cross-model evidence (5 frontier LLMs).
- CSEDB (Clinical Safety-Effectiveness Dual-Track Benchmark) — npj Digital Medicine, 2025 — nature.com — 10/10. Used for: 54.7% average safety score, 13.3% performance drop in high-risk scenarios (p < 0.0001). Models tested: DeepSeek-R1, OpenAI o3, Gemini 2.5 Pro, Qwen3-235B, Claude 3.7 Sonnet, MedGPT. Context: dataset is China-centric; models were English-trained.
- Ong et al. — "Large language model as clinical decision support system augments medication safety in 16 clinical specialties" — Cell Reports Medicine, 6(10):102323 (Oct 21, 2025) — pubmed.ncbi.nlm.nih.gov · DOI: 10.1016/j.xcrm.2025.102323 — 10/10. Used for: pharmacist + LLM co-pilot 1.5× accuracy on serious-harm errors. Methodology: prospective, cross-over, open-label study, 91 error scenarios, 40 clinical vignettes, 16 specialties.
Consumer behavior / access evidence
- West Health–Gallup Center on Healthcare in America survey — Published April 15, 2026; fieldwork Oct 27 – Dec 22, 2025. Sample: 5,660 US adults (Gallup Panel, nationally representative). Margin of error: ±2.1 percentage points at 95% confidence. eurekalert.org — 10/10. Used for: 14M US adults skipped a provider visit after AI guidance; 32% of under-$24K households used AI due to affordability versus 2% of over-$180K; 66M US adults (1 in 4) have used AI for health info in past 30 days.
- Rock Health 2025 Consumer Adoption of Digital Health Survey — Published March 2026, fieldwork Dec 2025. Sample: 8,000 US Census-matched adults. fiercehealthcare.com — 9/10. Supporting context: 32% AI chatbot use for health, up from 16% in 2024; 64% of AI users engage weekly+. Provides corroboration for the Gallup numbers.
India — healthcare infrastructure & deployment
- eSanjeevani telemedicine AI-assisted consultations — 282 million — Press Information Bureau, Government of India, February 13, 2026 — pib.gov.in — 9/10. Used for: scale evidence for Indian AI-first healthcare. Context: 282M total consultations April 2023 – Nov 2025; ~12M directly AI-assisted via Clinical Decision Support System (CDSS). The 282M figure is total platform throughput; the 12M is AI-specific.
- Ayushman Bharat Digital Mission — 799 million health IDs — PIB, as of August 2025 — pib.gov.in — 10/10. Used for: infrastructure context.
- Rural doctor-to-patient ratio 1:11,082 — Widely reported figure; WHO recommendation is 1:1,000. Sourcing: Borgen Project (Oct 2025), corroborated in multiple Indian health publications. borgenproject.org — 9/10. Derivation from the Indian Medical Council's physician registry divided by rural population estimates.
- ASHABot — GPT-4 WhatsApp chatbot for ASHA workers — Khushi Baby × Microsoft Research India; launched early 2024. Sourcing: Borgen Project (Oct 2025), Microsoft Research publications. borgenproject.org — 8/10. Used for: "800–900M rural Indians being reached through ASHA workers" — accurate scale framing of deployment goal.
Sources considered but not used
- ICMR "77% of Indian adults used AI for health queries in 2025" — rated 4/10, dropped. Could not locate ICMR primary document; single-source secondary attribution insufficient. Replaced with PIB-sourced 282M eSanjeevani figure.
- Wysa Hindi pilot clinical effect sizes (31% anxiety reduction, 40% depression reduction) — rated 6/10, dropped from final. Kept the 80% return rate as engagement signal. Clinical effect sizes require verifying the underlying study methodology; secondary summary insufficient.
- J&K "1 in 10 AI queries health-related, 32% above national average" — rated 7/10, not used. Considered for India usage hook but superseded by the harder eSanjeevani scale figure.